Abstract
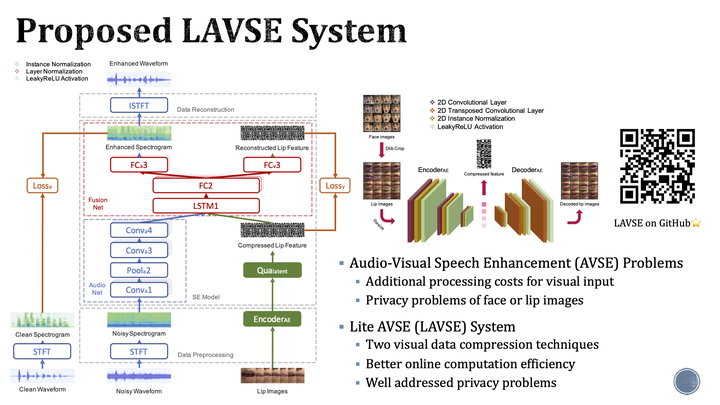
Previous studies have confirmed the effectiveness of incorporating visual information into speech enhancement (SE) systems. Despite improved denoising performance, two problems may be encountered when implementing an audio-visual SE (AVSE) system: (1) additional processing costs are incurred to incorporate visual input and (2) the use of face or lip images may cause privacy problems. In this study, we propose a Lite AVSE (LAVSE) system to address these problems. The system includes two visual data compression techniques and removes the visual feature extraction network from the training model, yielding better online computation efficiency. Our experimental results indicate that the proposed LAVSE system can provide notably better performance than an audio-only SE system with a similar number of model parameters. In addition, the experimental results confirm the effectiveness of the two techniques for visual data compression.
Shang-Yi Chuang
ML Researcher | ASR R&D
Extremely self-motivated engineer with excellent understanding of machine learning algorithms. Interested in speech processing, natural language processing, and multimodal learning.